02 渲染流水线
02 渲染流水线
概述
渲染流水线的最终目的在于生成或渲染一张二维纹理。
《Real-Time Rendering, Third Edition》 一书将渲染流程分为三个阶段:应用阶段,几何阶段,光栅化阶段。
应用阶段: 应用阶段通常由CPU负责,也就是说,开发者具有绝对的控制权。
在应用阶段有3个主要任务:
- 准备好场景数据,如摄像机的位置,视锥体,场景中使用的模型,使用的光源等等。
- 粗粒度剔除(culling):包括视锥体剔除(Frustum Culling)和遮挡剔除( Occlusion Culling)两种,前者用于剔除视锥体之外的物体,后者根据场景中Static物体的位置剔除其遮挡的物体。
- 设置好每个模型的渲染状态,这些渲染状态包括使用的材质,纹理,shader。
在应用阶段,最重要的输出是渲染所需的几何信息,即渲染图元(点、线、面等)。
几何阶段:几何阶段用于处理所有和要绘制的几何相关的事,主要负责把顶点坐标变换到屏幕空间中,再交由光栅器进行处理。这一阶段通常在GPU上运行。
光栅化阶段:主要决定每个渲染图元中的哪些像素应该被绘制在屏幕上,它需要对上一个阶段得到的逐顶点数据(纹理坐标,顶点颜色等等)进行插值,然后再进行逐像素处理。这一阶段也是在GPU上进行
渲染流水线
CPU流水线
应用阶段由CPU负责,大致分为3个阶段
把数据加载到显存中
- 所有渲染所需数据都从硬盘加载到内存中,网格和纹理数据被加载到显存中
设置渲染状态
- 渲染状态就是定义场景中网格如何被渲染,需要指定顶点着色器/片元着色器,光源属性,材质等
调用Draw Call
- Draw Call是一个CPU发起,GPU接收的命令,指向一个需要被渲染的图元列表,但不包含材质信息(上个步骤已经完成)
GPU根据渲染状态和输入的顶点数据进行计算,输出为像素(GPU流水线)
GPU流水线
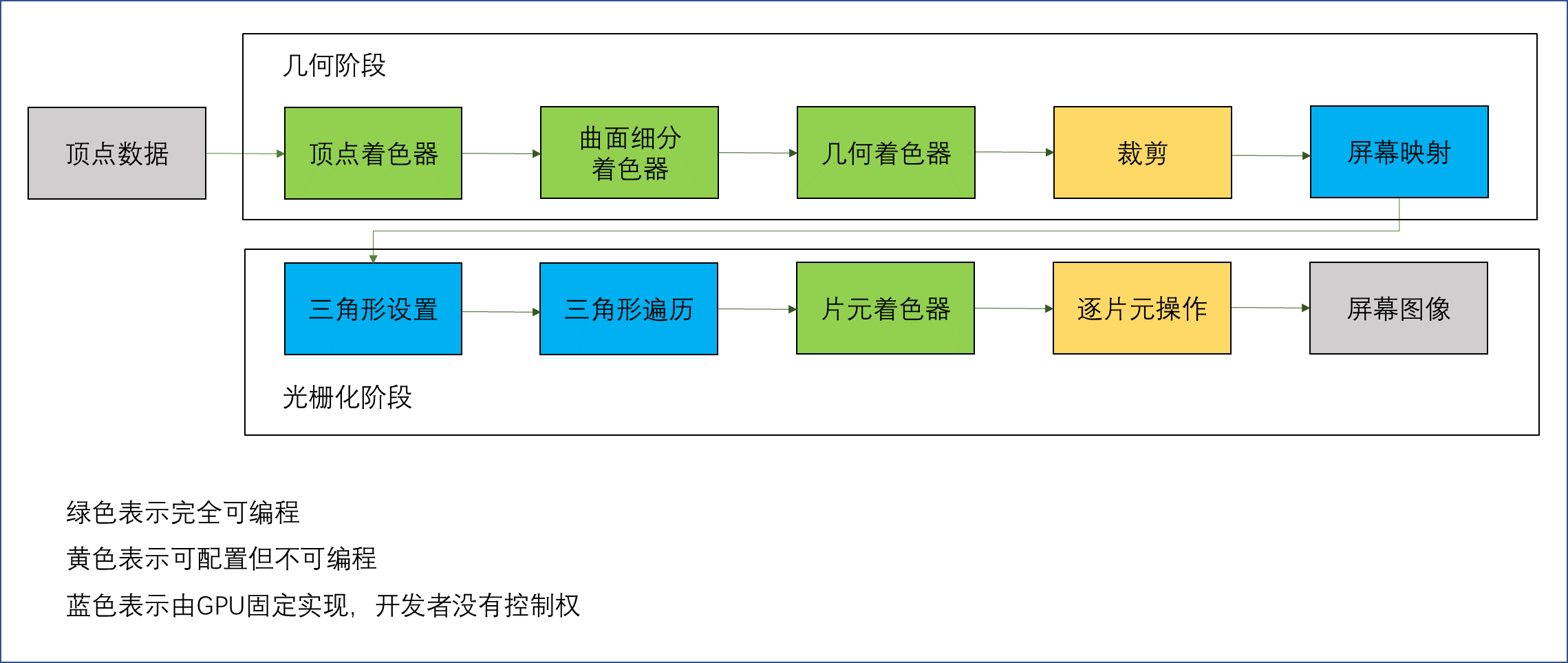
- 几何阶段的处理建立在顶点上
- 光栅化阶段的处理建立在三角形上
几何阶段
几何阶段:准备好几何图元,输出的信息是屏幕坐标系下的顶点位置以及与之相关的额外信息(深度值,法线方向,视角方向等)
顶点着色器
- 顶点着色器处理输入的每一个顶点,不创建或者销毁顶点。
- 每两个顶点都是独立的,无法得到顶点间的关系(如判断两个顶点是否属于同一个三角形网格),因此可以并行处理。
顶点着色器主要负责坐标变换和逐顶点光照,同时输出后续阶段的数据。
坐标变换:
- 对顶点的位置进行某种变换,可以模拟水面或布料等。
- 把顶点坐标从模型空间转换到齐次裁剪空间(模型空间->世界空间->相机空间->裁剪空间(视锥体的空间))。
- 输出每个顶点对应的纹理坐标。
曲面细分着色器
- 细分图元
几何着色器
- 逐图元(点,线,三角形面等)的着色操作或者用于产生更多图元。
- 顶点着色器以顶点数据作为输入数据,而几何着色器则以完整的图元(Primitive)作为输入数据。例如,以三角形的三个顶点作为输入,然后输出对应的图元。
- 与顶点着色器不能销毁或创建顶点不同,几何着色器的主要亮点就是可以创建或销毁几何图元,此功能让GPU可以实现一些有趣的效果。例如,根据输入图元类型扩展为一个或更多其他类型的图元,或者不输出任何图元。
- 需要注意的是,几何着色器的输出图元不一定和输入图元相同。几何着色器的一个拿手好戏就是将一个点扩展为一个四边形(即两个三角形)。
裁剪
- 将不在摄像机视野内的图元裁掉,将部分在摄像机视野内的图元裁剪处理。
- 几何阶段的裁剪不同于应用阶段的剔除,前者是剔除顶点,后者是剔除物体。
- 这一步是不可编程的,但是可以自定义一个裁剪操作。
屏幕映射
- 把图元的坐标转换到屏幕坐标中。
光栅化阶段
光栅化阶段:根据图元及相关信息着色
三角形设置
- 计算光栅化一个三角形网格所需的信息。
- 计算每条边上的像素坐标。
三角形遍历
- 逐一检查像素是否被三角形网格所覆盖,如果被覆盖,生成一个片元。
- 输出的是一个片元序列(一个片元=用于生成一个像素的状态合集,包括屏幕坐标、深度信息,以及其他从几何阶段输出的顶点信息,如法线,纹理坐标等)。
片元着色器
- 在DX中也称为像素着色器。
- 片元着色器的输入是由顶点着色器输出的数据插值得到的。
- 进行纹理采样,由顶点着色器输出的顶点对应的纹理坐标,经过三角形遍历和三角形设置的插值,得到片元对应的纹理坐标。
- 片元着色器也局限于单个片元,除了访问导数信息以外,单个片元不能与其邻居通信。
逐片元操作
- 在DX中称作输出合并阶段。
这一阶段涉及的任务有
决定每个片元的可见性,如模板测试、深度测试。
- 模板测试:片元的参考值和模板缓冲区中的值进行比较,从而决定片元的舍弃与否,同时自定义模板缓冲区的修改。通常用于限制渲染的区域,还可以实现渲染阴影,轮廓渲染等高级用法。
- 深度测试:片元的深度值和深度缓冲区中的值进行比较,从而决定片元的舍弃与否。通常用于实现可视和透明效果
如果一个片元通过了所有测试,就把它的颜色和颜色缓冲区中存储的颜色进行混合。
- 不透明的物体可以不进行混合,直接覆盖。
- 半透明物体需要使用混合。
- 这一阶段是可高度配置的。
其他技术
Early-Z
Unity使用的是Early-Z技术,在片元着色器之前进行深度测试。
- 但深度测试提前的话,其检验结果可能会与片元着色器中的一些操作冲突。
- 例如,我们在片元着色器进行了透明度测试,而这个片元没有通过透明度测试,我们会在着色器中调用API来手动将其舍弃。这就导致GPU无法提前执行各种测试。
现代的GPU会判断片元着色器中的操作是否和提前测试发生冲突,如果有冲突,就禁用提前测试。
双重缓冲
当模型的图元经过以上的计算和测试后,我们的屏幕显示的就是颜色缓冲区中的颜色值。
但是,为了避免我们看到那些正在进行光栅化的图元,GPU会使用双重缓冲的策略。
这意味着场景的渲染是在在后置缓冲中发生的,当场景已经被渲染到了后置缓冲中,GPU就会交换后置缓冲区和前置缓冲区,前置缓冲区是之前显示在屏幕上的图像。
其他
OpenGL/DirectX
开发者直接访问GPU是一件非常麻烦的事情,我们可能需要和各种寄存器、显存打交道。图像编程接口在硬件的基础上实现了一层抽象。
应用程序运行在CPU上。应用程序可以通过调用OpenGL或DirectX的图形接口将渲染所需的数据,如顶点数据、纹理数据、材质参数等数据存储在显存中的特定区域。
GPU可以在显存中存储任何数据,但对于渲染来说一些数据类型是必需的,例如用于屏幕显示的图像缓冲、深度缓冲等。
OpenGL和 DirectX就是这些图像应用编程接口,这些接口用于渲染二维或三维图形。可以说,这些接口架起了上层应用程序和底层GPU的沟通桥梁。
一个应用程序向这些接口发送渲染命令,而这些接口会依次向显卡驱动(Graphics Driver) 发送渲染命令,这些显卡驱动是真正知道如何和GPU通信的角色,正是它们把OpenGL或者DirectX的函数调用翻译成了GPU能够听懂的语言,同时它们也负责把纹理等数据转换成GPU所支持的格式。
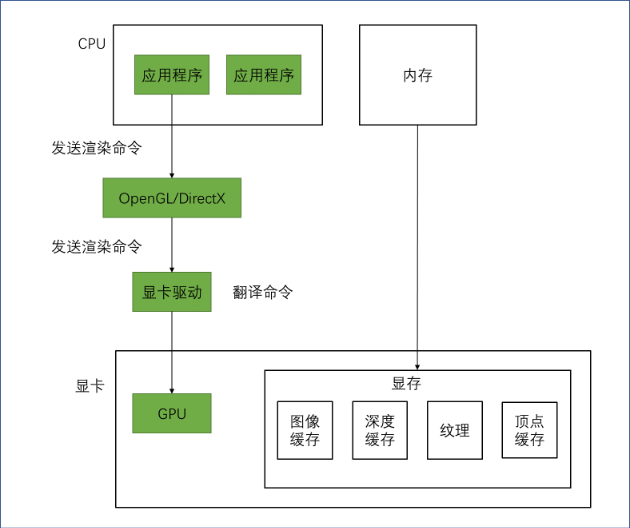
开发者可以通过图像编程接口发出渲染命令,这些渲染命令也被称为Draw Call,它们将会被显卡驱动翻译成GPU能够理解的代码,进行真正的绘制。
HLSL、GLSL、CG
着色语言是专门用于编写着色器的,常见的着色语言有
- DirectX 的 HLSL (High Level Shading Language)
- OpenGL 的 GLSL(OpenGL Shading Language)
- NVIDIA 的 CG (C for Graphic)。
HLSL、GLSL、CG都是“高级(High-Level)”语言,但这种高级是相对于汇编语言来说的,而不是像C#相对于C的高级那样。这些着色语言会被编译成与机器无关的汇编语言,也被称为中间语言(Intermediate Language,IL)。这些中间语言再交给显卡驱动来翻译成真正的机器语言,即GPU可以理解的语言。
对于一个初学者来说,一个最常见的问题就是,他应该选择哪种语言?
GLSL 的优点在于它的跨平台性,它可以在 Windows、Linux、Mac甚至移动平台等多种平台上工作,但这种跨平台性是由于OpenGL 没有提供着色器编译器,而是由显卡驱动来完成着色器的编译工作。也就是说,只要显卡驱动支持对GLSL 的编译它就可以运行。这种做法的好处在于,由于供应商完全了解自己的硬件构造,他们知道怎样做可以发挥出最大的作用。换句话说,GLSL是依赖硬件,而非操作系统层级的。但这也意味着GLSL的编译结果将取决于硬件供应商。要知道,世界上有很多硬件供应商——NVIDIA、ATI等,他们对GLSL 的编译实现不尽相同,这可能会造成编译结果不一致的情况,因为这完全取决于供应商的做法。
而对于HLSL,是由微软控制着色器的编译,就算使用了不同的硬件,同一个着色器的编译结果也是一样的(前提是版本相同)。但也因此支持HLSL 的平台相对比较有限,几乎完全是微软自已的产品,如 Windows、Xbox 360、PS3等。这是因为在其他平台上没有可以编译HLSL 的编译器。
CG则是真正意义上的跨平台。它会根据平台的不同,编译成相应的中间语言。CG 语言的跨平台性很大原因取决于与微软的合作,这也导致CG 语言的语法和HLSL 非常相像,CG语言可以无缝移植成HLSL代码。但缺点是可能无法完全发挥出OpenGL 的最新特性。
对于Unity平台,我们同样可以选择使用哪种语言。在Unity Shader 中,我们可以选择使用“CG/HLSL”或者“GLSL”。带引号是因为Unity里的这些着色语言并不是真正意义上的对应的着色语言,尽管它们的语法几乎一样。以 Unity CG为例,你有时会发现有些CG语法在Unity Shader中是不支持的。
Draw Call
在前面的章节中,我们已经了解了Draw Call 的含义。
Draw Call:CPU调用图像编程接口, 如OpenGL 中的gIDrawElements命令或者DirectX中的 DrawIndexedPrimitive命令,以命令 GPU进行渲染的操作。
CPU和GPU的并行工作
如果没有流水线化,那么CPU需要等到GPU完成上一个渲染任务才能再次发送渲染命令。但这种方法显然会造成效率低下。因此,我们使用一个命令缓冲区(Command Buffer),让CPU和 GPU可以并行工作。
命令缓冲区包含了一个命令队列,由 CPU向其中添加命令,而由GPU从中读取命令,添加和读取的过程是互相独立的。命令缓冲区使得CPU和 GPU可以相互独立工作。当CPU需要渲染一些对象时,它可以向命令缓冲区中添加命令,而当GPU完成了上一次的渲染任务后,它就可以从命令队列中再取出一个命令并执行它。
命令缓冲区中的命令有很多种类,而 Draw Call是其中一种,其他命令还有改变渲染状态等(例如改变使用的着色器,使用不同的纹理等)。
为什么Draw Call多了会影响帧率
在每次调用 DrawCall之前,CPU需要向GPU发送很多内容,包括数据、状态和命令等。在这一阶段,CPU需要完成很多工作,例如检查渲染状态等。而一旦CPU完成了这些准备工作,GPU 就可以开始本次的渲染。
GPU的渲染能力是很强的,渲染200个还是2000个三角网格通常没有什么区别,因此渲染速度往往快于CPU提交命令的速度。如果 Draw Call 的数量太多,CPU就会把大量时间花费在提交Draw Call上,造成CPU的过载。
如何减少 Draw Call
减少 Draw Call 的方法有很多,但我们这里仅讨论使用批处理(Batching) 的方法。
提交大量很小的Draw Call会造成CPU的性能瓶颈,即 CPU把时间都花费在准备Draw Call 的工作上了。那么,一个很显然的优化想法就是把很多小的 DrawCall 合并成一个大的Draw Call,这就是批处理的思想。
需要注意的是,由于我们需要在CPU 的内存中合并网格,而合并的过程是需要消耗时间的。因此,批处理技术更加适合于那些静态的物体,例如不会移动的大地、石头等,对于这些静态物体我们只需要合并一次即可。
当然,我们也可以对动态物体进行批处理。但是,由于这些物体是不断运动的,因此每一帧都需要重新进行合并然后再发送给GPU,这对空间和时间都会造成一定的影响。
在游戏开发过程中,为了减少Draw Call的开销,有两点需要注意。
避免使用大量很小的网格。当不可避免地需要使用很小的网格结构时,考虑是否可以合并它们。
避免使用过多的材质。尽量在不同的网格之间共用同一个材质。
固定管线渲染
固定函数的流水线(Fixed-Function Pipeline),也简称为固定管线,通常是指在较旧的GPU上实现的渲染流水线。这种流水线只给开发者提供一些配置操作,但开发者没有对流水线阶段的完全控制权。
固定管线通常提供了一系列接口,这些接口包含了一个函数入口点(Function Entry Points)集合,这些函数入口点会匹配GPU上的一个特定的逻辑功能。开发者们通过这些接口来控制渲染流水线。换句话说,固定渲染管线是只可配置的管线。一个形象的比喻是,我们在使用固定管线进行渲染时,就好像在控制电路上的多个开关,我们可以选择打开或者关闭一个开关,但永远无法控制整个电路的排布。
随着时代的发展,GPU流水线越来越朝着更高的灵活性和可控性方向发展,可编程渲染管线应运而生。我们在上面看到了许多可编程的流水线阶段,如顶点着色器、片元着色器,这些可编程的着色器阶段可以说是GPU进化最重要的贡献。
Shader
Shader 所在的阶段就是渲染流水线的一部分,更具体来说,Shader就是:
- GPU流水线上一些可高度编程的阶段,而由着色器编译出来的最终代码是会在GPU上运行的(对于固定管线的渲染来说,着色器有时等同于一些特定的渲染设置)
- 有一些特定类型的着色器,如顶点着色器、片元着色器等
- 依靠着色器我们可以控制流水线中的渲染细节,例如用顶点着色器来进行顶点变换以及传递数据,用片元着色器来进行逐像素的渲染。但同时,我们也要明白,要得到出色的游戏画面是需要包括Shader 在内的所有渲染流水线阶段的共同参与才可完成:设置适当的渲染状态,使用合适的混合函数,开启还是关闭深度测试/深度写入等。
Unity 作为一个出色的编辑工具,为我们提供了一个既可以方便地编写着色器,同时又可设置渲染状态的地方:Unity Shader